
时间:2015-08-14 09:19 来源:it168
【IT168 评论】这些天,全世界几十亿人都在疯传一个词,它的名字叫地球2.0,更有人亲切的称它为“地球之兄”,从此地球不再孤单了。而与地球2.0类似,还没来得及好好品味大数据1.0,大数据2.0就飞奔过来了。
在大数据2.0时代,我们缺少的不是数据,而是准确、高效驾驭数据洪流的方法、系统。随着数据的体积、速度和类型(volume、velocity和variety)在爆炸式递增,数据1.0时代经典的储存,操作系统及软件都将Out!我们可以看到,存储和计算方式被迫向各种分布式进化,操作系统向IAAS、PAAS进化,软件向SAAS进化。在这样的背景下,有一款神奇的产品出现了,它就是大数据操作系统,有人觉得,它的意义将不亚于当年DOS向WINDOWS系统进化的革命性成果。它与大数据平台有啥区别呢?我们邀请到了百分点的研发总监坐镇。百分点除了在个性化推荐系统上拥有很多行业的客户案例外,近年来深耕大数据领域,历经六年之久,打造出了一款明星产品,它的名字叫BD-OS,让我们一起来看看这背后的故事吧!
皮皮:您好!很高兴有机会采访到您,先简单介绍下自己吧!
刘总:从我个人经历来讲,我从事这个行业大概15年左右了,而数据成为了我整个职业生涯里面的灵魂。十年前我进入了Intel,主要负责Intel的搜索引擎优化的研究,侧重于视觉方向的搜索引擎。两年后到了一家北美公司Vitria负责复杂事件处理器(CEP)这套产品,这套产品可以理解为基于流的数据实时计算与处理系统。目前,已经有不少公司在采用Vitria的技术平台。持续了五年后,我转战到了Teradata公司,这是一家全球领先的大数据分析企业,我当时主要负责Teradata AsterData最核心的产品,这是一个内核分布式的数据库,我当时是在那家公司主要是参与数据库的内核的中国团队的主要成员之一。
真正踏入互联网行业差不多是在2012年以后,这三年里我先后在京东、搜狐等互联网企业负责大数据的挖掘与研发工作,所以回过头来看,数据成为了我整个职业生涯里最亲密无间的伙伴。
皮皮:您后来考虑到百分点公司,是否是机缘巧合?
刘总:这么多年来,我在数据方面积累了很多经验,衍生出了很多做数据产品的想法,但如果我考虑在大的互联网公司深入研发数据产品的话,空间资源上非常有限。刚好一个机缘巧合,我朋友给我介绍了百分点,百分点是一家专注于大数据技术产品的公司,在大数据方面,尤其是个性化推荐引擎方面,在业界已经比较知名了。在我看来,推荐引擎的功能是否强大,取决于幕后,它需要一整套完整的大数据技术体系和产品体系做支撑。百分点拥有的个性化推荐引擎,当时在业界已经非常知名了,它拥有了大量的客户,比如媒体和一些大型的传统行业。
皮皮:对电商来讲,一般做个性化的推荐有两种方式,京东很典型是要自己的人来做这块的推荐系统,我们的一号店用的是百分点的个性化的推荐系统,对于企业来讲,他是怎么样考虑这件事情,是选择做第三方来做个性化推荐系统还是用自己的人来做,他们在这种选择过程中需要考虑哪些因素?
刘总:对企业来讲,实际上有几点需要考虑,第一点,成本因素;企业现在是否能够承担或者是否愿意承担实现个性化推荐的产品和功能体系的代价,比如在人员的投入上、技术的支持上、还有数据层面上,是否有对应的支持;第二点,从横向角度来对比,哪种方式能够更好满足企业自身对推荐服务的需求。选用第三方推荐系统,比如百分点的推荐技术和产品,经过多年积累,百分点已经拥有了两千多家客户,企业可以享受到百分点丰富的数据成果。同样是对客户做用户画像分析,相对京东的推荐系统来讲,我们的产品在做个性化分析的时候,对客户的定义标签更为丰富,对一个人的了解更为全面和深入,所以我们能够更接近用户的需求。这两点可能是企业在选择过程中需要考虑的核心问题。
皮皮:经常网购的朋友,可能会注意到,电商网站会针对用户购物痕迹做一些个性化推荐,比如我们淘宝的浏览记录,我们的搜索关键词,我们的购买数据,我想问的是,你们个性化推荐引擎在采集数据的时候,是实时的,还是基于一定时间段的采集数据?像流数据相对离散数据而言,实时海量,对处理引擎的要求也非常高,这个技术难度非常高,你们是怎么做的?如何做到数据的实时同步?比如京东,最典型的拿618的数据和617的数据做推荐,如果没有办法做到流数据实时处理的话,一些数据出现延迟,很可能直接导致一些商业决策不够准确。
刘总:您说的基于流的推荐是实时推荐,这里面有两个难点,第一点是技术工程上,从开始的数据采集到加工挖掘、分析,这个流程里面,你是不是能够真正做到实时,或者你能够做到多快;第二点,我们现在用到的做推荐引擎的核心算法,大家都熟悉的基本理论大都是类似的,但在工程上要真正实现分布式的,这是一个坎,而实现分布式架构以后如何让算法做到基于增量数据的推荐,会更难一些;而进一步来说,基于实时的增量如何去做个性化的推荐那更是更难的,基于这两点,我们百分点在底层的这套BD-OS上有一套完整的架构,第一点,我们对于整个数据采集、落地、数据的接入、整合加工、挖掘这套流程,在我们这套系统内部可以实现一键式完成,第一是自动化、第二是这套系统可以自动流畅的运作,中间不会有太多人工参与;第二点,我们系统在CF协同过滤这种算法上做了一些改进,通过对CF算法的数学模型进行改进,让这种协同过滤从数学模型上首先能够适应实时增量的预测,基于改进后的数据模型,进而在工程上实现了一套特定的算法框架,这套算法框架再加上之前的整个数据流,被内置在底层的数据平台上,同时全部都是标准化的接口,这样的话,数据进来以后一气呵成。
皮皮:您刚才也提到基于这种标准化的接口,数据进来可以一气呵成,这可能会涉及到结构化数据和非结构化数据,怎么确保多样化数据实现一气呵成?
刘总:首先,我们把数据的处理生命周期分成四个阶段,第一个阶段是接入整合加消费,在每个阶段我们认为它都是一个体系,比如说在接入这个阶段,我们会有针对不同的数据类型或者是数据源类型,构建特定的接入系统。接入系统后数据会直接整合到后端的加工体系中。我只需要知道我的数据源的类型,然后提前适配好相应的接入系统,一旦数据开始生成,这个数据流就可以通过接入系统顺利流畅地落地到我的存储里面,存储里面会有相应标准的组件,让数据变得清晰,深度清晰,最终让数据变成真正有意义的数据,我们叫作信息,那就是当一个数据流从基础数据变成信息以后,意味着这个数据里面蕴涵着对特定行业或者是对业务逻辑的描述,价值。基于这个场景的话,就进入到第四个阶段,消费阶段,在有效的信息上面,我们会有很多标准化的分析模块、挖掘模块,这样的话,我们每次需要根据业务场景和客户需要变化的时候,只需要把有效的数据流、信息流对接到不同的分析模块或者是挖掘模块。只需要做这样的一个动作,我们就能得到相应的预测和分析结果,推荐引擎也是这样的原理。
皮皮:您刚才和我们详细聊到推荐引擎对数据整个生命周期的处理流程,我了解到,这些年百分点积累了很多行业案例,比如说电商、媒体、家电、快消品、汽车、还有零售等,那么从行业角度来讲,它们有一些差异,比如家电可能不是每秒钟都有交易量,但电商行业可能每秒钟都会产生交易量,你们给电商行业做个性化推荐与家电行业的个性化推荐有什么不一样的地方?是不是用同一套分析引擎?推荐算法是否有差异?推荐模型是否不一样?
刘总:肯定会有。这主要取决于两点,第一点是客户所在的行业和业务场景不一样,比如说电商,它在网上卖各种各样的商品,它的服务模式和长虹,华为或者是TCL不一样,对应网店卖电子产品的场景是不同的,这也导致它的数据更新频率和生成的数据量,以及数据维度有本质的区别,这是第一点;第二点,同样一个人,不同场景下,在网上购物,和他到门店里买东西,所留下来的信息量和维度是不一样的,这样的话,就导致我们对用户画像的维度、频率等综合指标也是完全不一样的。、对于电商行业来讲,用户会留下长期有规律的数据痕迹,通过这些频率数据、这些维度的数据,相对门店而言,它们所留下的维度数据要丰富得多。相比较而言,电商行业里面了解客户的深度和广度还有精准度,要更接近于真实情况,在门店的场景下可能会更少,只能是很模糊或者是很简单的描述,基于这两个,一个是行业应用不同,另外一个是客户留下的所谓的数据痕迹,数据足迹,或者是触点的丰富程度,或者是维度的不一样,在不同的行业中所做的推荐引擎也是有非常大的区别的。
皮皮:近日有一个新词备受关注,叫做地球2.0,而与之类似,大数据2.0也格外亲切。谈到大数据,大家一般都会联想到3个V,高容量(Volume)、高速度(Velocity)、多类型(Variety),那大数据2.0与大数据1.0有啥区别呢?在实际的场景中我们会感受到哪些变革?百分点又在大数据领域有哪些贡献?
刘总:实际上,大数据1.0和大数据2.0要解决的最终问题的目标是一致的。我有一个用户,有这么一个需求,我需要通过这套系统尽快得到我想要的结果,除了用户端的需求外,从数据,技术和产品的层面讲,实际上是从过去的七八十年代开始,第一代数据处理系统出现,一直到上个世纪九十年代末,互联网开始风行,我们整个人类世界,产生的数据源和数据量,还有数据产生的频率以及维度,在2015年的时间点来讲非常有限的,基于有限的容量、数据类型、数据频率之上,所构建出的数据处理系统,以及分析方法,也是和当时体量相对应的,那时代大概有二三十年的时间。
皮皮:我们也知道,百分点近期会有一个大的动作,推出一个大数据的操作系统,很多人可能也是第一次听到这个概念,相对来讲听到大数据平台的概念会更多,比如说像国外的一些厂商,像微软,IBM,他们都有自己的对应的大数据平台,最典型的他们也是基于这个Hadoop大数据平台,国内的有一些数据库厂商也慢慢开始做大数据平台了,我们想问,我们百分点的大数据操作系统,相对他们的大数据平台,有哪些差异?有哪些亮点?
刘总:是这样的,这个产品有几个特点,第一个,我们的百分点大数据操作系统BD-OS,它的核心是做数据处理,他以大数据的整合流程作为他的核心主线,也是他的主要的价值的蕴涵所在。
第二点就是我们知道现在世界上在业界里面已经有好多厂商基于Hadoop做了一些自己的产品。有一些叫数据平台,有一些叫数据操作系统。
皮皮:请问这个平台和操作系统是什么样的关系?
刘总:操作系统的特点是什么,操作系统首先有几个要素,第一点,它拥有自己的文件系统、标准的存储体系;第二点,基于操作系统之上,它有统一的资源管理系统;第三点,它有统一的任务调度体系来管理各种各样的作业;第四点,在这个体系之上,有一个标准的交互界面。目前在业界,叫得比较广泛的是大数据平台,因为在此之前,大家把很多种数据技术简单打包在一起,有一些数据平台下面可能对应多个文件系统。而这些文件系统之间没有依赖关系。在资源管理方面,数据平台下面每一个子系统都是单独管理自己的任务,管理自己的资源,这个大数据平台后面,对资源与存储、作业管理没有统一的体系,从用户视角来看,可以直接用数据平台所提供的各种各样的服务或者是技术,实现交互。比如说某些厂商有数据平台,里面有Hadoop,有大家熟悉的HBase,它们后台支撑的计算系统,所消耗的存储,对内存CPU的管理,对作业的管理,彼此之间都是割裂的,没有任何的关系,只是在统一的环境里做这个事。
之所以提出大数据操作系统这个概念,是因为在Hadoop 2.0之后,Apache Yarn和HDFS这两个技术逐渐一统江湖,很多计算框架都可以抛弃自己的资源管理还有文件系统,直接植根在HDFS之上,把自己的计算资源管理委托给Yarn管理,这样的话实际上原来的数据平台逐渐进化到了类似于操作系统的生命体征。这样一来,在这个数据平台下,所有的数据都放在一种类型的文件系统上,所以这个平台里面所有的内存资源,CPU资源,统一由一个调度中心来管理,所有的作业,目前来讲也有一些技术出现,能够逐步的去统一化管理。这样的话就完成了从最早的零散的工具箱式的数据平台,到数据操作系统的进化,这样一来,在资源和效率上,还有作业管理上都实现了飞跃,但是到这个层面以后,实际上我们发现有一个问题,虽然在底层后台完成进化,但是在前台只有很少一部分人用,或者说很少一部分人才能把它用起来。
皮皮:为什么大数据平台会提出这么高的门槛?
刘总:使用者需要了解各种各样的技术,别的不说,像Apache hadoop 体系里一些前瞻技术,比如Yarn、Spark等层出不穷的技术,当然Hadoop本身也在迭代,每天都会有一些新技术出现,要想做到运筹帷幄,首先要了解Apache的一些主流大数据技术,至少十几、二十种关键技术,同时还要驾驭每种技术的快速的迭代。真正要做到这两点的人才就很少,而且这些人才的成本非常高。无论是部署一套操作系统还是大数据平台,从部署到管理、运维就很难,如果在这些平台上要实现开发就更难了,对很多人而言,这些大数据平台完全是黑窗口,进去以后全是灰色的,除非你是一个大数据技术的高手,因此,使用者需要积累非常丰富的经验。
皮皮:大数据操作系统是一款重量级产品,实现的技术难度非常高,推出这么一款明星产品,你们大概花了多长时间?
刘总:我们花了六年的时间来研发这款大数据操作系统,一直在不断的做底层优化。从我的角度来讲,十多年一来,我一直在从事各种各样的数据处理的内核领域的工作,同时也有BPM的经历,从数据1.0时代演变到数据2.0时代,我们百分点通过积累多年的经验,推出了大数据操作系统,我们希望通过BD OS,能够帮助到更多的人,以更轻松的方式借助大数据技术来解决自己的问题,同时让更多的人提高效率。我们希望这样的产品,可以帮助到我们的企业,能够实现整个数据IT架构的平滑过渡,而且使用起来更快捷,便捷,这就是我们的初衷和目标。
皮皮:我了解到,你们推出的大数据操作系统BD-OS 是一套面向企业技术人员的 、 管理大数据采集 、 生 产 和应用环节 所 有 资 源 和 任 务 的 操作系统。能不能从技术的角度讲一下BD-OS 的架构?
刘总:首先在底层我们可以适配大多数大数据技术或者是大数据平台的产品,我们总结过去大家踩过的坑,期待这个操作系统能够完成从Dos到windows的进化。
在底层的数据处理上,BD-OS具有系统化、智能化、可视化等特点。换句话说,数据处理标准、流程会内置于系统中,用户没必要纠结于复杂的流程和细节。同时 ,我们通过一些图形化界面、操作说明的向导,引导用户进入标准化和流程化的数据处理中。BD-OS提供了可视化的图形操作界面,通过拖拽、配置、搭积木的可视化方式实现复杂处理场景。
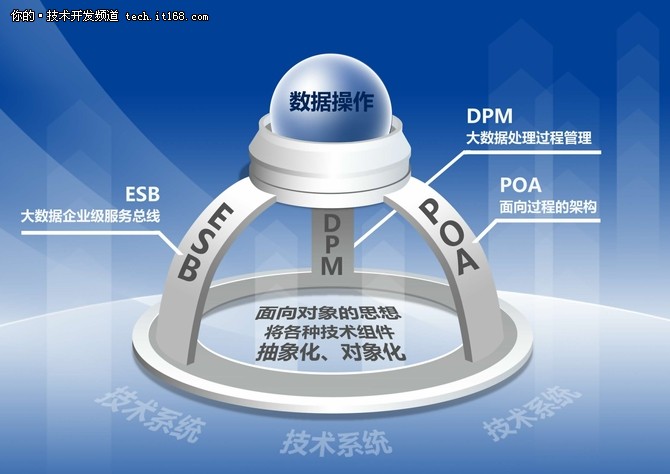
它可以实现一站式数据管理,在采集阶段,BD-OS完全支持采集业务系统数据、系统日志数据、互联网用户行为数据、互联网开放数据,亦可对接第三方数据源。我们提供了数据过滤、数据加密等多种数据清洗工具。BD-OS可以实现多源异构数据的整合,支持标准的数据仓库建模模型,提供交互式即席查询,让用户在海量数据上迅速验证自己的Idea。
从中层的数据流程管理来看,BD-OS将数据技术和数据流程之间变成了一种标准化、流程化的交互式连续迭代的关系,以 数 据 处 理 流 程为中心, 通过统一编程 , 建模 、组合流程 , 集成创 建 工 具 来 构 建和部署解决方案。
从顶层架构来讲,面向对象是我们的一个出发点,我们朝这个方向逻辑去解决大数据的技术产品化的问题。具体到我们的BD-OS层面上,我们会有POA,就是面向过程的架构,从这个意义上讲,架构为流程服务,通过内置面向流程架构实现了高度协调和集成。我们借助这种思想重构了大数据的所有技术,也就是让用户直接把这个技术作为一个对象来用,只需要了解对象的属性就可以了,没必要搞清楚底层是如何运作的,通过定义好我们的数据处理,流程架构,这种架构颠覆了传统的模式,实现了数据业务驱动来定义IT架构。
对客户而言,只需要弄清楚自己的一套数据处理流程规范,通过定义好的流程来自动生成相应的技术架构的过程,或者是技术模板。我们的用户和企业,为了满足自己的需求,会做各种各样的数据处理工作,有可能每个需求背后需要一条或者多条数据来满足。企业在实际过程中,可能会遇到很多业务需求或者是产品化需求,在我们BD-OS平台上,用户可以通过拖拽、配置、搭积木的可视化方式实现复杂处理场景,明确数据流的过程,自动生成相应的数据IT系统,然后就可以自动工作。这就好比在一个车间里,有很多种产品,这个车间里就会对应很多条流水线。企业干的事,就是定义好这些流水线,把它设计好、画好,真正的问题是底下真正是怎么实现的,同时流水线多了以后,流水线本身也有一些问题,有一些要修改,有一些要增加新的业务流程,我们这个产品就是能帮助用户管理, 这就是我们所说的DPM数据流程管理。
皮皮:处于互联网+的一个风口上,云计算与大数据越来越火了,您能否分享下大数据的操作系统的前景?
刘总:互联网+最大的特点是什么?我认为,在于它有大量的新数据源诞生,基于这些新的数据源,有特定的技术去解决,比如说传感器、监控等各种各样的新型电子设备。怎么把数据沉淀下来,做有效的数据分析处理,是我们需要重点考虑的因素。无论是在云端还是在本地,BD-OS平台可以提供全链路大数据工具解决方案,让用户一站式完成从数据接入到报表生成的全过程,实现企业的自助决策和多维分析,让业务定位更精准。比如我们可以为用户提供优秀的报表、舆情监测等服务。
免责声明:本文仅代表作者个人观点,与商务财经网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
| 栏目更新 |
| 栏目热门 |
商务财经网介绍|投资者关系 Investor Relations|联系我们|法律义务|意见反馈|版权声明
商务财经网Copyright©《中国工业和信息化部网站备案许可证》编号:京ICP备17060845-2



